Networked Notebooks & Engineered Serendipity
I’ve spent the last little bit playing with GPT3 and Dall-E mini (don’t have Dall-E access yet), including pitching my colleagues at Carbon on a few use cases, none of which have been good ideas so far.
Using this to work out a thought about interesting use cases I’ve come across, how you’d build them, some issues, and how you might ultimately commercialize them.
The promise of GPT3
For this, I’ll use the 2 of the embeddings GPT-3 calls out in their system: classification and topic clustering
The way I currently think about GPT3 is as a tool that can do transformations of large bodies of text, both faster than a human and with more stateful memory. Tactically this means one way to find value is to look at existing large bodies of text and think of what transformations might accelerate the way we receive value from those bodies of text (or might make things that previously were not valuable, valuable). What I mean by “large bodies of text”:
- CRMs
- Word processors
- Customer support
- Excel
- Jira
- Books
- Notebooks/note apps
- Contracts
The short term approach (which is probably what we’ll see first) is people building plugins on top of existing products or platforms to extend them. For example, this might be a function to apply GPT3 to the files in your Google Drive (see this example for looking up state populations). I think the most transformational change will happen when our tools are re-imagined from the ground up with this GPT3 at the core. If done right, we’ll write faster, remember better, infer meaning more quickly. If done wrong, idiocracy probably.
Even relational notebooks are silo-ed
In today’s world, you infer relationships through search; you search a word or a tag, Google Drive shows you every document that includes the word you searched either directly or in the metadata. Roam shows you a preview so you can extract meaning, and allows you to link notes explicitly. In both cases the default use case of the notebook is input only, and you can only extract insight or meaning asynchronously (ie after taking notes, through the process of search, by seeking relationships out).

The problem of extracting meaning from large bodies of text interests me because I’m both a voracious producer and consumer of text; in my personal life for memory, to work out a thought, or to record ideas, and at work for decision alignment, communication, and more. For example, I’ve had an idea notebook that I started in 2013 because I thought at some point I’d build all of them:

At some point I realized I’d never get to them all, and that if I didn’t either a) write them down or b) build them, they’d haunt me. In that notebook, there are several ideas that I’ve written down multiple times A problem I frequently encounter when taking notes is returning to different variants of the same idea years later; this is a little bit of how my mind works and I (assuming I’m not unique in this) am probably just processing the idea in the back of my head over time, and as soon as some new stimulus appears that has some relationship with the idea, a different version of it appears and leaves me obsessed until I either do it or write it down. For example, I’ve long been obsessed with the great pacific garbage patch, and a few years ago became obsessed with the concept of genetically engineering an organism that would feed on the plastic as an input, and have some harmless/benign waste product, and then releasing that organism into the great pacific garbage patch to gradually reduce it over time. (the bacteria + plastic idea has some promise, but releasing a genetically engineered organism into the wild is probably a terrible idea, please don’t do it). Anyway, if you search “plastic” in my idea notebook, you’d get 17 entries. This is the first - me writing out the idea in 2015:
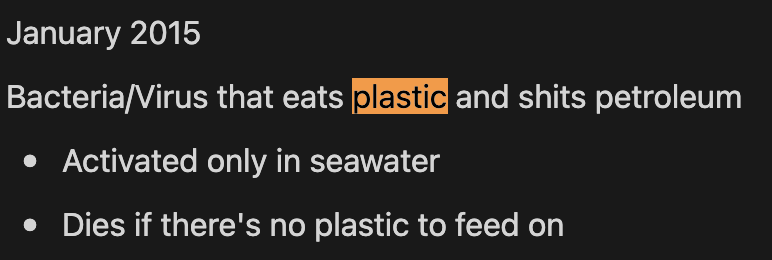
Most likely this idea hit me after reading a variant of this study: https://www.science.org/doi/10.1126/science.aad6359 . And I come back to it 5 years later, without much evolution in the idea, probably triggered by something I read (looks like I didn’t link to the originating context)

And again in 2021:

And later in 2021, I read a paper that reignites the idea:

And most recently, I come back to it again in May 2022:
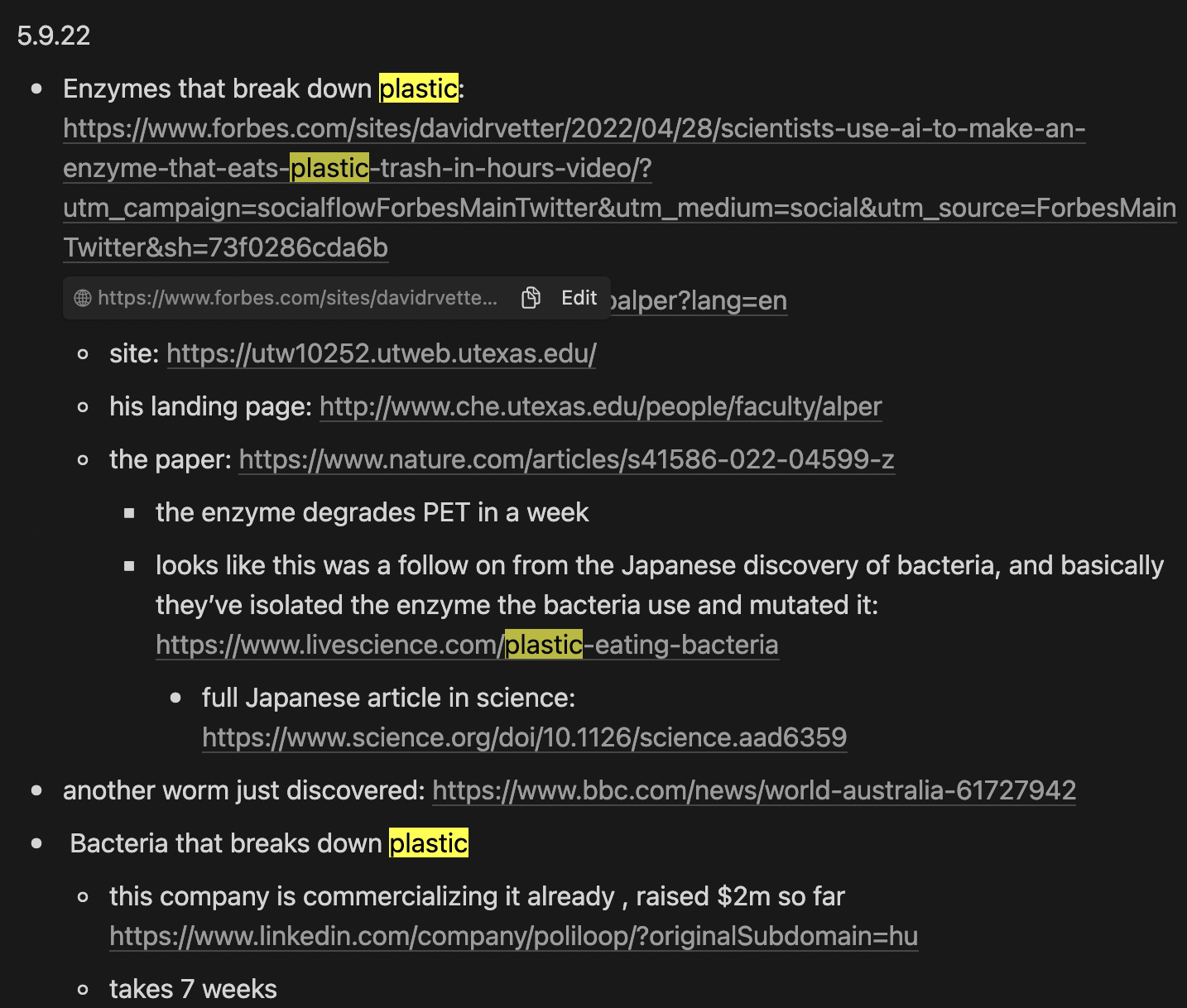
Between 2015 when I read the initial paper and 2022, multiple things have happened. First, the research space has advanced meaningfully, but the idea has not meaningfully advanced in my head, despite me repeatedly coming back to it. Second, the process of me stumbling on more recent research that’s directly in or adjacent to the topic is purely incidental/serendipitous. Third, the commercialization has started to advance - people have started building companies around this same domain. Finally, the main advantage my notebook had over paper in this case, was giving me a search bar so I could find references more easily.
Notebooks can network
A GPT-3 first notebook can be a faster, more proactive search bar. This is something that even highly polished products like Notion don’t try, and relational notebooks like Roam and Reflect have tried to do for a while; explicitly and proactively infer relationships between current and previous entries, and in so doing enable you to extract meaning.
Using GPT-3’s classification and topic clustering embeddings, you can
- extract insight at a higher level of abstraction (ie this topic is related to this other topic, rather than this same word is present in both notes)
- surface that insight to the writer in real time, during the writing process, to influence what they are writing
This combination creates a feedback loop that’s not otherwise available; meaning extracted or inferred from a previous entry, can influence the current input while it’s being written. In 2019 I wrote this

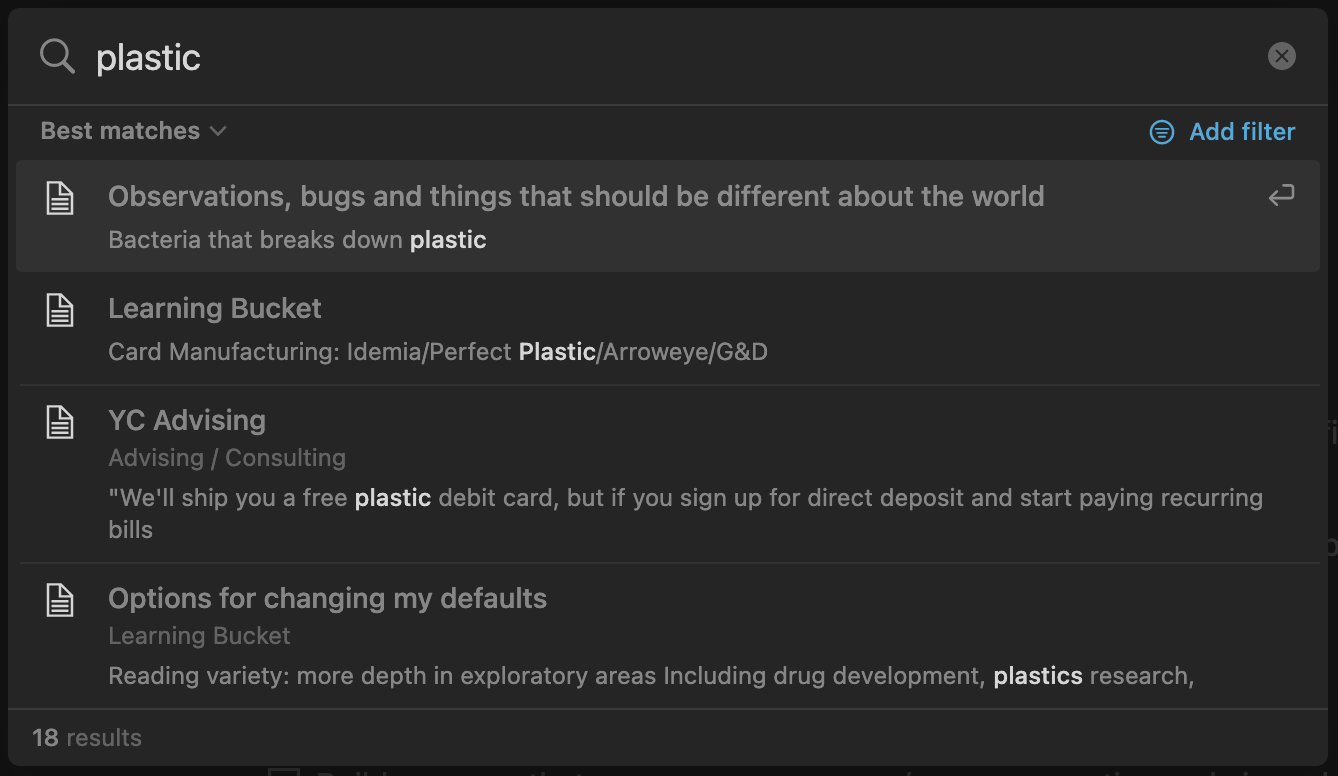
This topic is literally one and the same; the entire objective of the bacterial idea is to apply it to the great pacific garbage patch, but my notebook does nothing to link these two ideas together. If you search for plastic, you get a variety of results that share the same search term but aren’t necessarily related.
The promise of GPT3 here is to use topic classification and clustering to help you realize that what you’re writing now is related to something you’ve written or recorded before, at the level of meaning (ie you’re writing about waste disposal) rather than at the level of a linked word (ie you typed “plastic” so we’re going to pull up every reference to plastic). This is a step function change from static notes (microsoft word), notes in the cloud (google drive), notebooks with database functionality (notion, coda) or relational notebooks (Roam, Reflect).
Use cases for Networked Notebooks
Note applications or word processors today have a simple multiplayer mode; multiple people can edit documents at the same time. Single player mode for networked notebooks is simple; show me related topics in real time as I write. There are a few vectors for multiplayer mode in networked notebooks that are quite interesting and AFAIK haven’t been done in a notebook before; corporate, social, platform and search.
Corporate networks
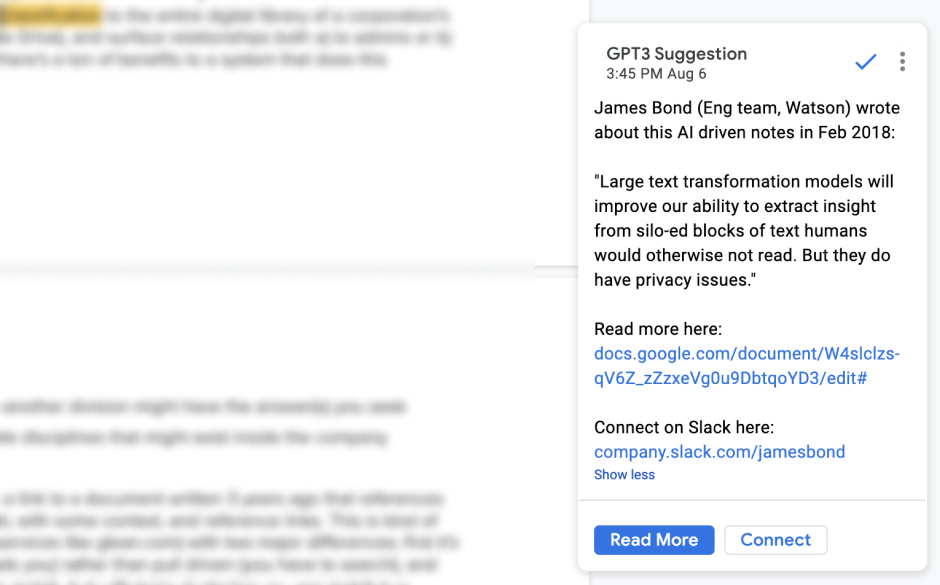
Corporate network formation is the simplest and most obviously commercial use case. In this case you’d apply topic clustering and classification to the entire digital library of a corporation’s documents (Eg your company’s Google Drive), and surface relationships both a) to admins or b) to employees in the course of work. There’s a ton of benefits to a system that does this proactively;
- Helps prevent duplicative work
- Creates serendipity - a colleague in another division might have the answer(s) you seek
- Helps manifest insight across multiple disciplines that might exist inside the company
The model here can simply be: here’s a link to a document written 3 years ago that references the topic you’re currently writing about, with some context, and reference links. This is kind of similar to enterprise network search (services like glean.com) with two major differences; first it’s proactive and push driven (context finds you) rather than pull driven (you have to search), and second, search relies on two strings to match, but with topic clustering you can match two “insights” which means that even if there’s minimal overlap in what exactly was entered into the search bar, related insights can easily find each other and be suggested to the writer(s), who can then either ignore it, or utilize it by enriching their current piece.
 .
.
Socially networked notebooks
This is probably the most subversive use case with the greatest potential for spam, but the greatest positive externalities. Your notebook is private by default, and you’re anonymous by default (same as today) but your topics are public by default, and whenever you have a topic collision between you and another writer on the network, the notebook suggests a double opt-in introduction; “hey someone else with [x] background has written about this topic 3 times over the last 5 years, would you like to connect”.

If both note-takers agree, the system puts them in touch. Here, the benefits are immense:
- With the right level of abstraction, you’ll discover others in other disciplines with overlapping interests
- This will probably drive much faster knowledge creation than would be organically possible
- It gives each writer full control over what gets shared and what disciplines they connect with
- Topic clustering helps you shield specifics about your topic, while sharing enough to learn about potential external partners.
However, as in any open communication protocol, there’s some phishing risk. With this model, it's quite possible to topic phish; create topics and present your identity in a way that exposes others who might otherwise want to stay private, to you.
Platform
This involves proactive surfacing topics across all a single player’s platforms to them, regardless of where the source is; drive, notion, slack, email etc. Same benefits as single player, just like playing on multiple fields at the same time.
Search
This is about enriching your notebook with bodies of knowledge that already exist, outside of you. The simplest is updating your notes with Google searches. Richer models for this would include searching research papers directly using linked citations, clustering topics within them directly, and pulling those clusters into your notebook in realtime and proactively; imagine if every time you came to a notebook about a topic, the most recent research related to the topic you were taking notes about was included and the relevant parts were summarized and linked.
A way to think about this is; imagine if you’re drawing something you don’t yet know is an elephant; a week ago you drew the legs, yesterday you drew the tail, today you’re drawing the trunk - at its best, insight extraction = the notebook suggesting the missing part of the drawing, so you get to the point faster.
Privacy
This might not matter, but one thing I don’t know how to solve in this model is privacy. Right now a lot of the largest bodies of text (and by extension areas with the greatest leverage for using transformations) are private by default, and to make this work,
you need to expose them to an outside organization that didn't have access to them before.
For example, your personal Notion site, Google docs or Roam might also contain extremely personal content; the unintended consequences of having everyone’s personal notes used as a training set for a large ML model is something I don’t have a good way to think about.
Engineering Serendipity
The macro insight here is that both in our personal and professional lives, there are lots of large bodies of text which are quite expensive to run transformations or anything other than simple analytics on. This means that in many cases, whatever signal exists in these documents is often lost or easy to miss. GPT-3 makes it possible to extract some of that signal far more cheaply than a human would. The net result would, if sufficiently accurate, expand creativity. I started with notes because it’s personally interesting, but there’s all sorts of use cases where a large body of text contains some meaning that’s quite expensive to extract.
When I describe engineering serendipity, what I'm really saying is that there's some information out there in the world (written by someone I don't know, or written by someone else in my company) that would be mutually beneficial to me or to the writer, if either of us knew about each other and that we shared overlapping interest in the topic. This benefit could be literally financial (as in we have a shared economic interest) or personal (as in we would take great pleasure in knowing that we are not alone in this thought) or anything in between. Historically this has been difficult to accomplish because writing styles are sufficiently different and it's difficult to permission a document in a way that allows only strangers who share the same insight as you, but might not have written it yet, to find the document you wrote. Large language models help solve this in two ways; first by making it possible to extract meaning while shielding both parties and then second by identifying relationships between both "meaning extractions" and suggesting them, thus allowing a double opt-in model that does not expose your content directly until you're comfortable doing so. The acceleration of thought and the relationships this can foster, have simply not been possible before today. As more remote work becomes more widespread, and more organizations work asynchronously through documents, the ability to engineer serendipity has the potential to replace some of the lost wonder of bumping into a colleague by the watercooler.
Thanks to Aaron Frank and Nico Chinot for reading this in draft form.
To get notified when I publish a new essay, please subscribe here.